Why was S3 a Game-Changer for Cloud Storage?
Explore the fundamentals of Amazon S3, its uses, and alternatives. Learn how cloud storage supports businesses and developers, with tips for hosting and insights on integration.


n March 14, 2006, Amazon Web Services launched S3, the Simple Storage Service. It was introduced as a reliable, scalable way to store data in the cloud, and it quickly became a foundational service for AWS. Yet the true innovation was not the storage itself, but the model it embraced and the interface it exposed.
S3 was built on object storage, a concept already known in enterprise circles but largely inaccessible to smaller organizations. By pairing that model with a web-friendly API and usage-based pricing, Amazon made object storage practical for developers everywhere. The S3 API soon became the standard way to interact with object-based storage, replicated across cloud providers and embedded into countless tools and applications.
In this article, we will take a closer look at object storage, how S3 became the de facto protocol for it, and how you can use S3 or S3-compatible services in your next project.
What Is Object Storage?
Modern digital workloads produce vast amounts of unstructured data. Photos, videos, documents, logs, machine learning datasets, and backups are not easily managed by traditional storage systems. Object storage was designed to solve that problem.
In a traditional file system, data is organized using directories and file paths. This structure works well on a local computer but becomes difficult to scale. File systems often enforce limits on the number of files in a directory or total metadata entries, and performance suffers as these limits are approached. In distributed environments, managing file locks, consistency, and replication adds further complexity.
Block storage offers another option, providing raw volumes that require a file system to be layered on top. This model is well suited for transactional systems and databases, but it is not ideal for storing discrete files like media assets or logs.
Object storage takes a fundamentally different approach. Each file is stored as a self-contained object, paired with a unique identifier and customizable metadata. Objects are placed in a flat namespace and accessed via API rather than traditional file paths. This makes them ideal for storage systems that must scale horizontally and handle billions of files without degrading performance.
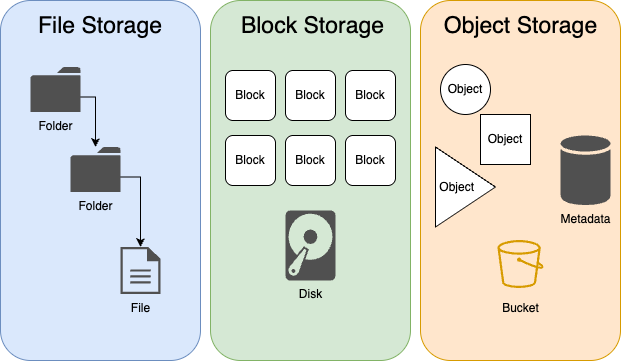
Although object storage lacks true directory structures, it can simulate a hierarchy using metadata. Prefixes in object names, often separated by slashes, allow many platforms to display folders and paths through their interfaces. This is a convenience for users, but internally, all objects exist in a single logical space.
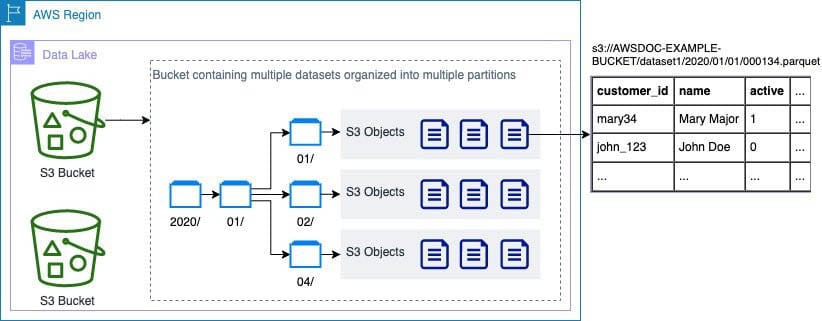
The result is a system that scales seamlessly, supports distributed access by design, and integrates easily into automated workflows and cloud-native environment.
From Enterprise to Accessible
Before 2006, object storage was mostly found in enterprise systems. Vendors like EMC and IBM provided dedicated appliances capable of storing petabytes of data with redundancy and compliance features. These systems were reliable, but costly and tightly integrated into proprietary ecosystems. Deploying one required significant investment and specialized expertise.
Amazon Web Services needed something more flexible. As cloud infrastructure matured, so did the demand for storing user-generated content, logs, backups, and application data. Traditional storage models could not meet these needs at cloud scale.
S3, built on object storage principles, was the solution. It exposed a simple web-based API that developers could use to store and retrieve data. There was no need to configure volumes, manage partitions, or worry about hardware. Data could be uploaded directly to a bucket and accessed on demand, with high durability and minimal complexity.
By making object storage affordable, accessible, and designed for automation, S3 transformed a niche enterprise technology into a fundamental building block for modern applications.
Protocol or Service
S3 began as an internal AWS solution for scalable storage, but the way developers interacted with it quickly became the real innovation. Rather than relying on traditional file access methods, S3 introduced a web-based API. This interface allowed developers to store and retrieve objects using straightforward HTTP operations. It was stateless, programmable, and easy to integrate into applications.
At its core, the S3 protocol is a web-based interface built around standard HTTP verbs like GET, PUT, DELETE, and POST. Each operation is scoped to a named bucket and a key that identifies the object. Authentication is handled through access keys and signatures, while requests are signed to verify integrity and permissions. The protocol supports features like multipart uploads, versioning, and server-side encryption, all accessible through well-documented endpoints. Because it is stateless and designed for parallelism, it scales well in distributed systems and integrates cleanly into modern development workflows.
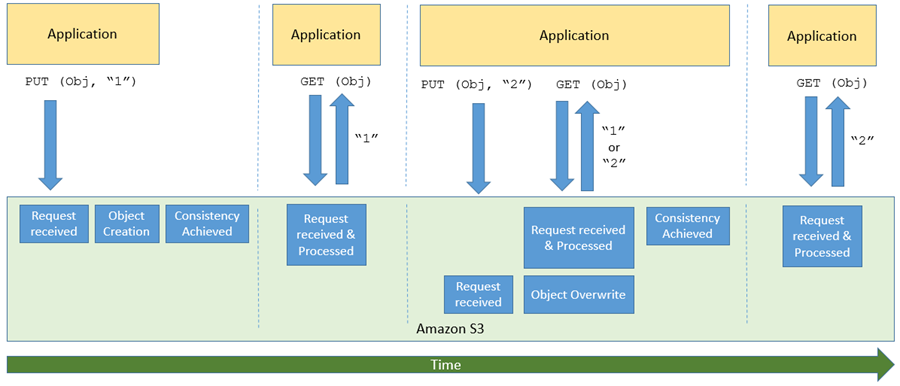
Over time, the S3 API became more than just a way to access Amazon’s storage service. It evolved into a common interface for object storage across the cloud industry. Developers wrote tooling and automation around it. Libraries and SDKs adopted it as a default. Systems expecting cloud storage began to assume S3 compatibility.
There was never a formal standardization process, but the ecosystem made its choice. The S3 API became the protocol most often used to interact with object storage, whether or not Amazon was involved.
The Expanding Ecosystem
The popularity of the S3 interface encouraged other providers to build compatible services. Offering an S3-compatible API allowed these companies to tap into an existing ecosystem of software, tools, and workflows. Developers could switch platforms without rewriting their applications or learning a new storage model.
Several cloud platforms now offer S3-compatible services, each with its own focus and advantages:
- Digital Ocean: Known for their developer-friendly cloud services, Digital Ocean offers Spaces, an S3-compatible object storage service. It's designed to be easy to use and is integrated with Digital Ocean's other cloud services.
- Wasabi: Focused on providing affordable and high-performance cloud storage, Wasabi's service is fully S3-compatible. They emphasize lower storage costs and faster speeds compared to traditional cloud providers.
- Google Cloud Storage: Google offers storage solutions that are compatible with the S3 API through their Google Cloud Storage service. This service is part of the broader suite of cloud computing services offered by Google Cloud.
- Backblaze B2: Known for their cost-effective storage solutions, Backblaze B2 offers an S3-compatible API. This makes it easier for users to migrate or use applications originally designed for Amazon S3.
- OVH: Leveraging OpenStack architecture, OVH's S3-compatible object storage offers a robust, scalable, and open-source solution, ideal for businesses seeking flexible and customizable cloud storage.
- Cloudflare: Cloudflare's S3-compatible storage service, R2, stands out with its integration with their world-class CDN, ensuring ultra-fast content delivery across the globe.
Each provider offers different pricing, performance, and availability models. What unites them is the shared goal of supporting the S3 API, making it easier for users to move between platforms and find the service that best fits their workload.
A Flexible Protocol
The impact of the S3 API extends far beyond cloud service providers. It has influenced how both object storage and traditional storage systems are architected and exposed to users.
In distributed storage platforms like Ceph, the S3 interface can be layered on top its RADOS backend using a gateway. This allows a Ceph cluster, which stores data using its custom Reliable Autonomic Distributed Object Store (RADOS), to present itself as an s3-compatible object storage system. Applications expecting S3 can interact with Ceph seamlessly, even though the underlying architecture is different.
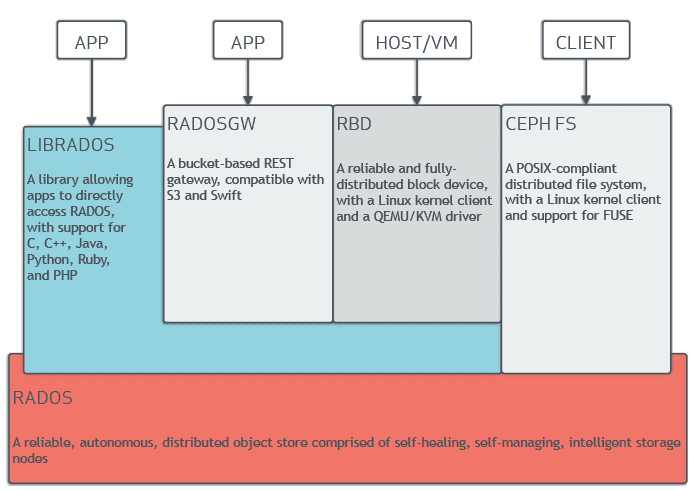
Conversely, object storage can be adapted to behave like traditional file systems. Tools like FUSE allow S3-compatible buckets to be mounted and browsed as if they were local directories. This makes object storage usable in legacy workflows, shell scripts, and applications that require filesystem semantics. Behind the scenes, every file operation is translated into API calls.
These two examples highlight the adaptability of the S3 interface. Whether presenting a custom storage solution as object storage or treating object storage like a filesystem, the S3 API provides a consistent way to interact with data. Its flexibility has helped establish it as more than just an implementation detail. It is now a core building block of how systems are designed, accessed, and extended across the modern storage landscape.
Use Cases for Object Storage
There is no single way to use S3. To some, it is a backend for application infrastructure. To others, it is a long-term archive, a dataset repository, or even a public distribution system.
Developers frequently rely on S3-compatible storage for hosting static assets such as images, scripts, fonts, and downloadable resources. These files are served directly over HTTPS and can be easily integrated into websites and applications. Since object storage scales automatically and supports public access configuration, it is often used to deliver content globally without setting up complex infrastructure.
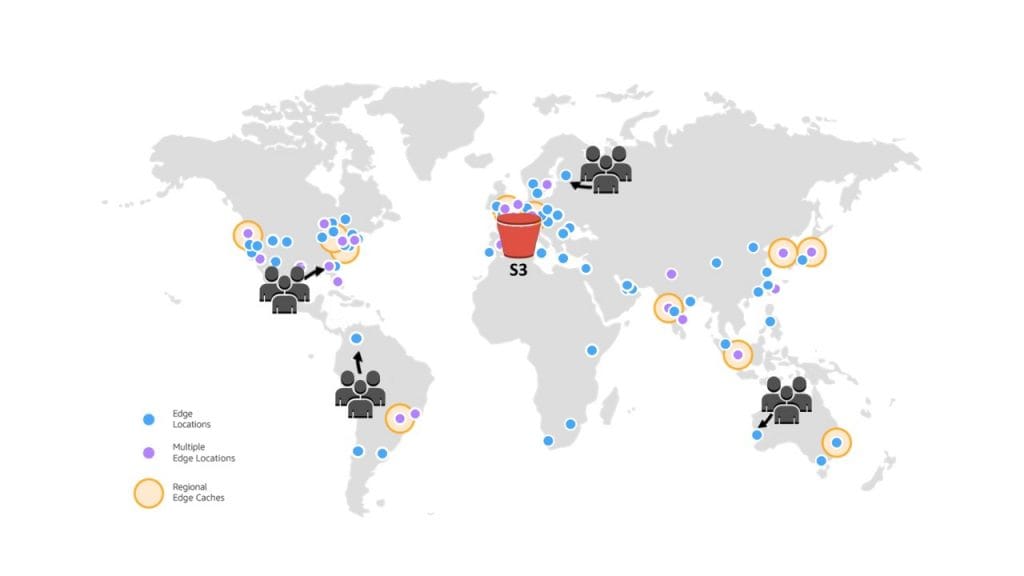
When paired with a content delivery network (CDN), object storage becomes a simple and efficient distribution platform. Assets stored in buckets can be cached and served from edge nodes around the world, significantly improving performance for users. This approach is widely used in static website hosting, software update delivery, and media streaming, where consistent global performance is critical.
For teams working in data analytics or machine learning, object storage provides a reliable and scalable way to store large datasets. These datasets can be accessed directly by analytic engines and training systems without needing to move them into a separate database. Object storage supports the kind of high-concurrency access patterns typical of distributed analysis tools, which may launch hundreds or thousands of parallel processes to read and process data. On platforms like Amazon S3, the underlying infrastructure automatically scales to meet demand, provisioning more hardware to serve data from a heavily accessed bucket when necessary.
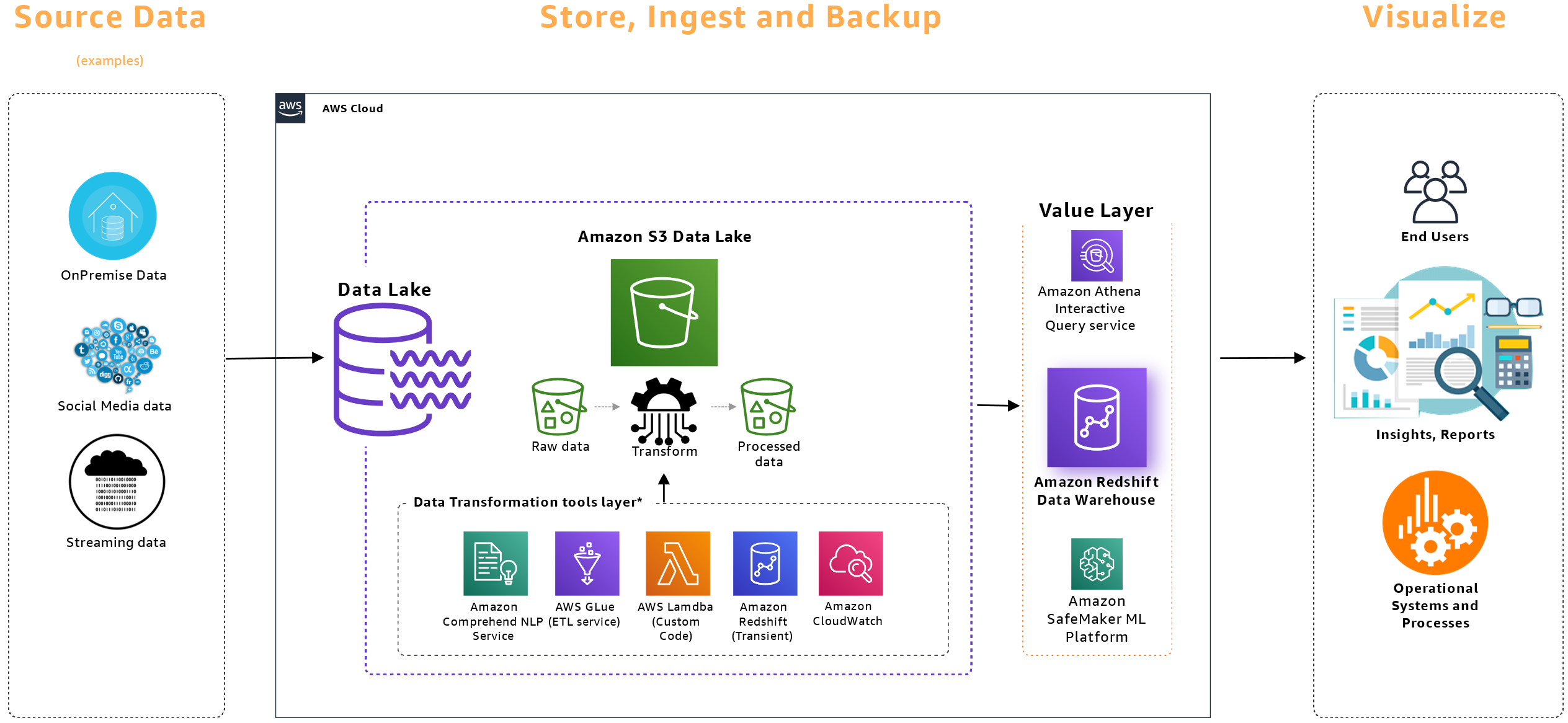
Object storage is also commonly used for automated backups and long-term archival. Applications and infrastructure components can push data directly to an S3-compatible bucket as part of routine snapshot or export processes. Lifecycle rules allow older files to transition automatically into colder storage classes, keeping costs low while preserving access to historical data. Built-in features like immutability and replication make this an attractive option for compliance and disaster recovery.
MinIO - Self Hosted S3
For teams and individuals seeking full control over their object storage infrastructure, MinIO offers a high-performance, open-source solution that faithfully implements the S3 API. Designed for scalability and resilience, MinIO is particularly well-suited for deployment on dedicated hardware with direct access to physical drives.
MinIO’s architecture is optimized for distributed deployments across multiple nodes. Each node hosts its own storage devices, which splits content into data and parity blocks distributed across the cluster. This allows the system to tolerate drive or node failures without losing availability or integrity. MinIO deployments can also span geographic regions using site replication, creating an additional layer of fault tolerance and disaster recovery. To maintain performance and ensure data locality, each node typically runs on bare-metal hardware with high-throughput network access and minimal abstraction between the application and the disk.

MinIO's compatibility with the S3 API means that existing tools and applications designed for AWS S3 can interact with MinIO without modification. This makes it an ideal choice for hybrid environments where workloads span both on-premises and cloud infrastructures. Users can leverage familiar tools and workflows while maintaining complete control over their data.
By deploying MinIO on dedicated hardware, users can achieve enterprise-grade object storage performance and reliability without incurring the costs associated with commercial cloud services. This approach is particularly appealing for organizations with stringent data sovereignty requirements or those seeking to optimize storage costs.
How to Start?
Before adopting an object storage solution, it helps to clearly define the use case. Consider the type of data being stored, how often it will be accessed, and what kind of guarantees are needed for durability, redundancy, or compliance. These factors will guide the choice between a hosted service like AWS S3 or a self-managed solution such as MinIO.
Most cloud providers offer free tiers or usage-based pricing models that make it easy to experiment. Services like Backblaze, and Cloudflare allow new users to test S3-compatible APIs without long-term commitments. For those interested in building internal infrastructure, MinIO can be deployed on spare hardware to simulate a production workflow.
Setting up S3-compatible storage typically begins with creating access credentials and provisioning a bucket. From there, files can be uploaded using web interfaces, command-line tools like s3cmd, aws-cli, or MinIO’s own mc tool. Most programming environments also offer well-supported libraries for interacting with S3. Python developers often use boto3, while Node.js projects might rely on the AWS SDK. For Go, minio-go provides a lightweight alternative, and Java developers can turn to the AWS Java SDK.
Once in place, object storage becomes just another component in the stack. Whether used for archiving, deployment, analysis, or content delivery, it operates quietly in the background, doing exactly what it was designed to do—store and serve data reliably, at scale.
Next Steps
Amazon S3 did not invent object storage, but it did redefine how developers and organizations interact with it. By exposing a clean, scalable API and eliminating the need for specialized hardware or contracts, S3 made object storage practical for a much wider audience. Over time, that interface became a standard. Today, the S3 API is used by cloud providers, self-hosted systems, and infrastructure tools alike.
Whether building something on AWS, running a private MinIO cluster, or selecting a provider based on cost and performance, adopting object storage is no longer just about where the data lives. It is about how that data is accessed, managed, and integrated into broader systems.
S3 started as a service, but it became a protocol—flexible, portable, and foundational.
2025-05-24 : Article updated to offer a broader view of S3 and its role in the cloud ecosystem.



